打开Python爬虫实战练习C03页面 爬虫实战练习C03,看到页面上是鸢尾花数据集(Iris Dataset)。先点击“立即验证”看看这一关要求校验什么数据,发现是要求“Sepal Width列的总和”。
回到C03的页面,把页面都浏览一遍。在页面底部发现了有分页的页码。
这时候先按快捷键 F12 打开浏览器开发者工具,切换到 Network 标签,点击其中一个页码,发现浏览器向 scraper-practice-c03 这个地址发送了一个 POST 请求。点击这个请求,在开发者工具右边切换到 Payload 选项卡,发现了以下的发送参数:
{
xorResult: 1744472901,
random: 8827,
timestamp: 1744472903,
hash: "347443ae0a3ff6eabc80b48b117b867e"
}
回到页面上,右键 -> 查看页面源码,发现分页页码调用了一个 getIrisData() 函数,并把页码作为参数传递了进去,并且在 html 源码的第 384 行发现了这个函数,函数名正常显示,但其它 JavaScript 代码都被加密混淆了。
根据经验,这种情况就有两种解决方法:一种就是使用 Selenium;另外一种就逆向这段 JavaScript。我们是在练习爬虫,不做选择,全都要!
先尝试 Selenium 来爬取页面,先找到页码的 xpath 表达式,因为我们等一下需要通过 Selenium 自动化点击。并且记住总页数,因为我们需要循环点击进行翻页,可以直接跳过第一页的点击,因为打开就是第一页了,不用点就出来了。同时也要分析出 Sepal Width 数据列的 xpath 表达式,因为我们要获取数据进行计算。
基于 Selenium 的爬虫核心代码如下:
client = webdriver.Chrome()
client.get(url)
time.sleep(5)
html = client.page_source
# print(html)
for i in range(1,5):
client.find_elements(By.XPATH, '//ul/li/a')[i].click()
time.sleep(5)
html = client.page_source
client.quit()
以上爬虫代码使用 Selenium 打开页面后输出 html 源码并进行解析,然后点击第二页重复上述操作,直至最后一页。
接下来我们就开始第二种方法:逆向 getIrisData() 函数的 JavaScript 代码。
回到开发者工具,切换到 Sources (源码)选项卡,最左侧 Page 那里有个树形菜单,找到并点击 scraper-practice-c03,就能看到 html 源码在中间展开了。找到我们刚才的 getIrisData() 函数所有的第 384 行,因为加密混淆的原因,这个函数的代码是在同一行里面的。这样不利于我们分析代码,这时候有个调试 JavaScript 代码的小技巧:点击代码左下角的大括号就能把代码格式化成便于阅读分析的格式。
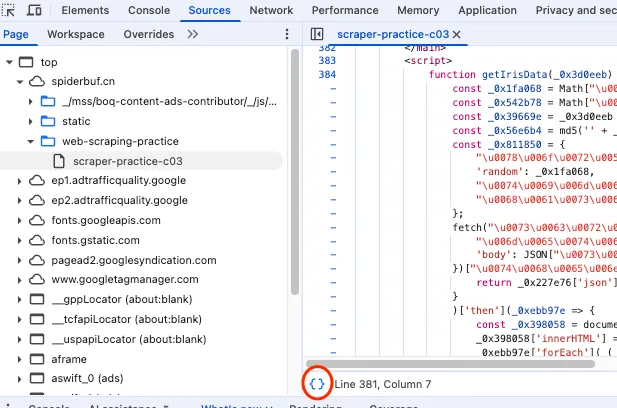
在格式化后的 getIrisData() 函数内任意一行下个断点,然后刷新页面再点击任意的翻页页码,就发现代码停在了断点处,并且右边的 Local 处出现了函数前几个变量的值。如果断点断得比较靠前没有出现全部变量的值,可以按 F10 一行一行执行 JavaScript 代码。
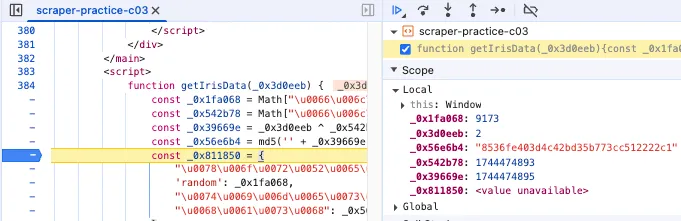
此时把光标移动到类似 \u0066 这样的 Unicode 编码上,就能看到这些编码后的内容。而 0xbe628 这样的字符串在 JavaScript 开发语言中代表十六进制数值。 结合前面的 Payload,我们就能根据这些值对应起每个变量的意义:
- _0x39669e = xorResult # 出现了 JavaScript 异或计算符号 ^
- _0x1fa068 = random # 出现了 random 关键字
- _0x542b78 = timestamp # 出现了 now 关键字
- _0x56e6b4 = hash # 出现了 md5 关键字
通过操作系统自带的计算器,把十六进制的值转换后就能得到十进制的值,并且可以直接利用计算器的计算功能计算出如:(0xba7af ^ 0xbb8ef) 的值( ^ 对应计算器上的 xor)。结合以上的分析可以写出 getIrisData() 函数生成请求参数的 JavaScript 代码如下:
function getIrisData(pageno){
const randomNum = Math.floor(Math.random() * 8000 + 2000);
const timestamp = Math.floor(Date.now() / 1000);
const xorResult = pageno ^ timestamp;
const _md5 = md5(`${xorResult}${timestamp}`).toString();
const payload = {
xorResult: xorResult,
random: randomNum,
timestamp: timestamp,
hash: _md5
};
...
}
有了业务逻辑我们就可以使用 Python 编写爬虫代码了:
pageno = 1
random_value = random.randint(2000, 10000)
timestamp = int(time.time())
xorResult = pageno ^ timestamp
md5_hash = hashlib.md5()
md5_hash.update(f'{xorResult}{timestamp}'.encode('utf-8'))
hash = md5_hash.hexdigest()
payload = {
'random': random_value,
'timestamp': timestamp,
'hash': hash,
'xorResult': xorResult
}
# print(payload)
json_response = requests.post(base_url, headers=myheaders,json=payload).text
print(json_response)
json_data = json.loads(json_response)
for item in json_data:
print(item)
这样一来,我们就能直接通过 Python 代码向接口发送 POST 请求并直接获取 Json 数据了。然后对这些 Json 数据进行解析及统计就能得到我们这一关的答案了。
完整的爬虫案例代码:爬虫案例代码